- Topic1/3
246 Popularity
270 Popularity
234 Popularity
15k Popularity
15k Popularity
- Pin
- #Gate 2025 Semi-Year Community Gala# voting is in progress! 🔥
Gate Square TOP 40 Creator Leaderboard is out
🙌 Vote to support your favorite creators: www.gate.com/activities/community-vote
Earn Votes by completing daily [Square] tasks. 30 delivered Votes = 1 lucky draw chance!
🎁 Win prizes like iPhone 16 Pro Max, Golden Bull Sculpture, Futures Voucher, and hot tokens.
The more you support, the higher your chances!
Vote to support creators now and win big!
https://www.gate.com/announcements/article/45974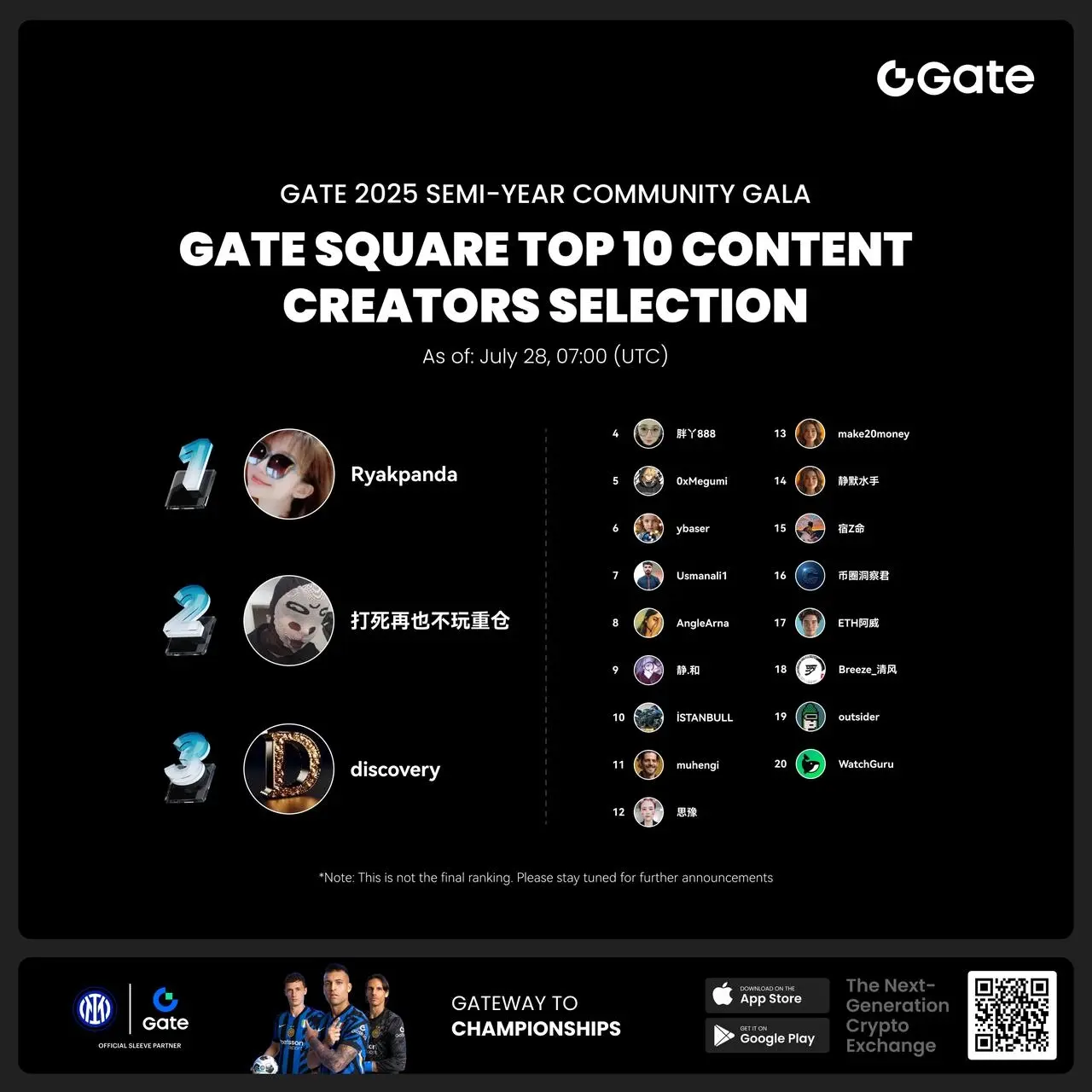
- 🎉 Hey Gate Square friends! Non-stop perks and endless excitement—our hottest posting reward events are ongoing now! The more you post, the more you win. Don’t miss your exclusive goodies! 🚀
1️⃣ #ETH Hits 4800# | Market Analysis & Prediction: Boldly share your ETH predictions to showcase your insights! 10 lucky users will split a 0.1 ETH prize!
Details 👉 https://www.gate.com/post/status/12322612
2️⃣ #Creator Campaign Phase 2# |ZKWASM Topic: Share original content about ZKWASM or its trading activity on X or Gate Square to win a share of 4,000 ZKWASM!
Details 👉 https://www.gate.com/post/st
TokenBreak Attack Bypasses LLM Safeguards With Single Character
HomeNews* Researchers have identified a new method called TokenBreak that bypasses large language model (LLM) safety and moderation by altering a single character in text inputs.
The research team explained in their report that, “the TokenBreak attack targets a text classification model’s tokenization strategy to induce false negatives, leaving end targets vulnerable to attacks that the implemented protection model was put in place to prevent.” Tokenization is essential in language models because it turns text into units that can be mapped and understood by algorithms. The manipulated text can pass through LLM filters, triggering the same response as if the input had been unaltered.
HiddenLayer found that TokenBreak works on models using BPE (Byte Pair Encoding) or WordPiece tokenization, but does not affect Unigram-based systems. The researchers stated, “Knowing the family of the underlying protection model and its tokenization strategy is critical for understanding your susceptibility to this attack.” They recommend using Unigram tokenizers, teaching filter models to recognize tokenization tricks, and reviewing logs for signs of manipulation.
The discovery follows previous research by HiddenLayer detailing how Model Context Protocol (MCP) tools can be used to leak sensitive information by inserting specific parameters within a tool’s function.
In a related development, the Straiker AI Research team showed that “Yearbook Attacks”—which use backronyms to encode bad content—can trick chatbots from companies like Anthropic, DeepSeek, Google, Meta, Microsoft, Mistral AI, and OpenAI into producing undesirable responses. Security researchers explained that such tricks pass through filters because they resemble normal messages and exploit how models value context and pattern completion, rather than intent analysis.
Previous Articles: