ИИ + Веб3: Башня и Площадь
Статья затрагивает возможности Web3 в стеке технологий искусственного интеллекта, включая совместное использование вычислительной мощности, защиту конфиденциальности данных, обучение моделей и вывод, а также изучение того, как искусственный интеллект усиливает финансы, инфраструктуру и новые повествования Web3, от децентрализованных сетей вычислительной мощности до холодного старта искусственного интеллекта, от безопасности транзакций на цепочке до генеративных NFT, интеграция искусственного интеллекта и Web3 открывает новую эру, полную инноваций и возможностей.TL;DR:
- Проекты Web3, основанные на концепции искусственного интеллекта, стали привлекательными целями для инвестиций на первичном и вторичном рынках.
- Возможности для Web3 в отрасли искусственного интеллекта заключаются в: использовании распределенных стимулов для координации потенциального предложения в длинном хвосте - в области данных, хранения и вычислений; тем временем установление модели с открытым исходным кодом и децентрализованного рынка для AI Агентов.
- AI играет ключевую роль в индустрии Web3, в основном в онлайн-финансах (криптовалютные платежи, торговля, анализ данных) и помощи в разработке.
- Полезность AI+Web3 заключается в дополнительности двух: ожидается, что Web3 противодействует централизации искусственного интеллекта, а искусственный интеллект ожидается поможет Web3 освободиться от ограничений.
Введение
За последние два года развитие искусственного интеллекта ускорилось, как бабочковый эффект, инициированный Chatgpt, открыв новый мир генеративного искусственного интеллекта и вызывая тенденцию в далеком мире Web3.
С благословением концепции искусственного интеллекта финансирование криптовалютного рынка значительно увеличилось по сравнению со замедлением. По данным СМИ, только за первое полугодие 2024 года общее количество 64 проектов Web3+AI завершили финансирование, и операционная система на базе искусственного интеллекта Zyber365 достигла наивысшей суммы финансирования в размере 100 миллионов долларов США в раунде серии A.
Вторичный рынок более процветающий, и данные с зашифрованного агрегатора веб-сайтов Coingecko показывают, что всего за год общая рыночная стоимость трека искусственного интеллекта достигла 485 миллиардов долларов, суточный объем торгов составил почти 86 миллиардов долларов; очевидные преимущества, принесенные основным прогрессом в области технологий искусственного интеллекта, после выпуска модели текст-видео от OpenAI под названием Sora, средняя цена сектора искусственного интеллекта выросла на 151%; эффект искусственного интеллекта также распространился на один из секторов криптовалютного золото-поглощения Meme: первый концепт MemeCoin AI Agent - GOAT быстро стал популярным и достиг оценки в 1,4 миллиарда долларов, успешно запустив волну AI Meme.
Исследования и темы об AI+Web3 одинаково популярны. От AI+Depin до AI Memecoin и до текущего AI Agent и AI DAO, эмоция FOMO уже отстала от скорости новой повествовательной ротации.
AI+Web3, это сочетание терминов, полное горячих денег, трендов и фантазий о будущем, неизбежно рассматривается как брак, устроенный капиталом. Кажется, что нам трудно отличить, является ли это родным грунтом для спекулянтов или предвестником рассвета под этим великолепным платьем.
Для ответа на этот вопрос ключевым соображением для обеих сторон является, станет ли другая сторона лучше? Смогут ли они извлечь пользу из паттернов друг друга? В этой статье мы также пытаемся рассмотреть эту ситуацию с точки зрения встать на плечи предшественников: Как Web3 может сыграть роль в различных аспектах стека технологий искусственного интеллекта, и какую новую жизненную силу может принести искусственный интеллект в Web3?
Какие возможности у Web3 под стеком искусственного интеллекта?
Перед тем, как мы погрузимся в эту тему, нам необходимо понять технический стек больших моделей искусственного интеллекта:
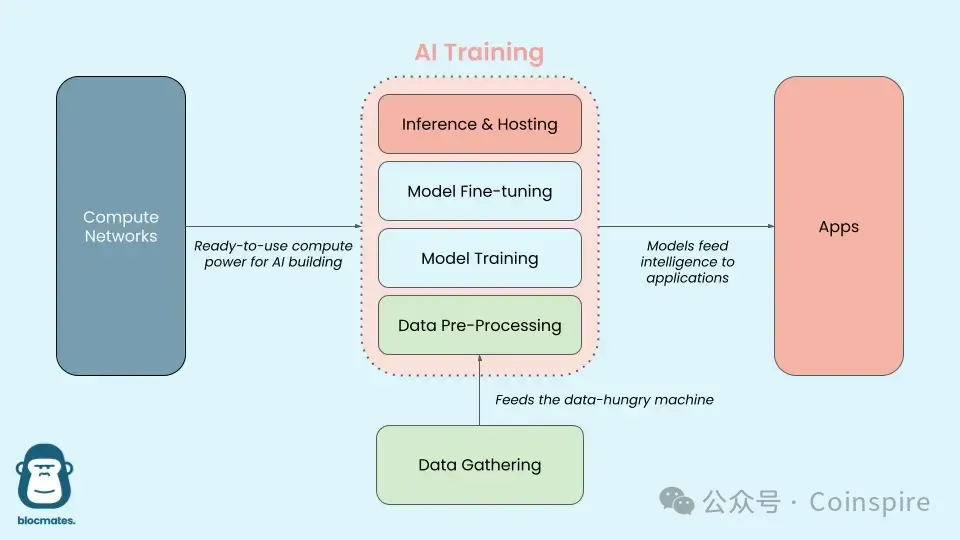
Источник изображения: Delphi Digital
Проще говоря, «большая модель» похожа на человеческий мозг. На ранних этапах этот мозг похож на новорожденного младенца, который только что появился в мире и нуждается в наблюдении и усвоении огромного количества внешней информации, чтобы понять мир. Это этап «сбора» данных; поскольку компьютеры не обладают множеством чувств, как люди, перед обучением большое количество неаннотированной внешней информации нужно «предобработать», чтобы преобразовать ее в формат, который компьютеры могут понять и использовать.
После ввода данных ИИ создает модель, способную понимать и предсказывать через «обучение», которое можно рассматривать как процесс того, как малыш постепенно понимает и учится о внешнем мире. Параметры модели подобны языковым способностям, которые малыш постоянно корректирует в процессе обучения. Когда обучающее содержание начинает специализироваться или когда оно получает обратную связь от общения с людьми и делает корректировки, оно входит в этап «тонкой настройки» больших моделей.
По мере взросления дети учатся говорить, понимать значения и выражать свои чувства и мысли в новых разговорах, что похоже на «вывод» крупных моделей искусственного интеллекта. Модель может предсказывать и анализировать новые языковые и текстовые вводы. Дети выражают свои чувства, описывают объекты и решают различные проблемы с помощью языковых способностей, что также похоже на применение крупных моделей искусственного интеллекта в различных конкретных задачах на этапе вывода после завершения обучения, таких как классификация изображений, распознавание речи и т. д.
В то время как искусственный интеллект (AI) приближается к следующей форме крупных моделей - способности самостоятельно выполнять задачи и преследовать сложные цели, обладая не только способностью мыслить, но и умением запоминать, планировать и взаимодействовать с миром с помощью инструментов.
В настоящее время, решая проблемы ИИ в различных стеках, Web3 начальным образом сформировал многоуровневую взаимосвязанную экосистему, охватывающую различные этапы процессов моделирования ИИ.
Сначала базовый уровень: Airbnb вычислительной мощности и данных
Вычислительная мощность
В настоящее время одной из самых высоких затрат на ИИ является вычислительная мощность и энергия, необходимая для обучения моделей и вывода моделей.
Одним примером является то, что для завершения обучения в течение 30 дней требуется 16 000 H100GPUs от NVIDIA (высокопроизводительное графическое ускорительное устройство, разработанное специально для искусственного интеллекта и высокопроизводительных вычислительных нагрузок) для Meta's LLAMA3. Версия на 80 ГБ стоит от 30 000 до 40 000 долларов, требуя аппаратных инвестиций в размере от 4 до 7 миллиардов долларов (GPU + сетевые чипы). Кроме того, ежемесячное обучение потребляет 16 миллиардов киловатт-часов, с энергозатратами почти 20 миллионов долларов в месяц.
Для разгрузки вычислительной мощности искусственного интеллекта, это также самое раннее поле, где Web3 пересекается с ИИ - DePin (децентрализованная сеть физической инфраструктуры). В настоящее время на веб-сайте данных DePin Ninja отображается более 1400 проектов, включая представительные проекты по совместному использованию вычислительной мощности графических процессоров, такие как io.net, Aethir, Akash, Render Network и т. д.
Основная логика заключается в том, что платформа позволяет физическим лицам или организациям с неиспользуемыми вычислительными ресурсами предоставлять свою вычислительную мощность в децентрализованном режиме без разрешения, увеличивая использование малоиспользуемых вычислительных ресурсов через онлайн-рынок, аналогичный Uber или Airbnb для покупателей и продавцов, обеспечивая конечным пользователям получение более экономичных и эффективных вычислительных ресурсов; в то же время механизм стейкинга также гарантирует, что в случае нарушения механизмов контроля качества или сетевых сбоев, поставщики ресурсов столкнутся с соответствующими штрафами.
Его особенностями являются:
- Объединение неиспользуемых ресурсов GPU: Поставщики в основном являются сторонними независимыми малыми и средними центрами обработки данных, избыточные вычислительные ресурсы от операторов, таких как криптовалютные шахты, и майнинговое оборудование с механизмами консенсуса PoS, такие как FileCoin и ETH miners. В настоящее время также существуют проекты, посвященные запуску устройств с более низкими барьерами входа, такие как exolab, использующие местные устройства, такие как MacBook, iPhone, iPad, для создания сети вычислительной мощности для запуска выводов крупномасштабных моделей.
- Столкнувшись с долгим рынком вычислительной мощности ИИ: a. «С технологической точки зрения» децентрализованный рынок вычислительной мощности более подходит для рассуждений. Обучение полагается в большей степени на возможности обработки данных, обеспечиваемые супербольшим кластером масштабных GPU, в то время как рассуждения относительно менее требовательны к вычислительной производительности GPU, такие как Aethir, фокусирующийся на работе с низкой задержкой и приложениях вывода ИИ. b. «С точки зрения спроса» потребители небольших и средних вычислительных мощностей не будут индивидуально обучать свои собственные большие модели, а лишь выберут оптимизацию и тонкую настройку вокруг нескольких основных моделей, и эти сценарии естественным образом подходят для распределенных ресурсов простоя вычислительной мощности.
- Децентрализованное владение: Технологическое значение блокчейна заключается в том, что владельцы ресурсов всегда сохраняют контроль над своими ресурсами, гибко их настраивают в соответствии с спросом и при этом получают прибыль.
Данные
Данные являются основой искусственного интеллекта. Без данных вычисления бесполезны, и отношение между данными и моделями подобно пословице 'Мусор на входе — мусор на выходе'. Количество и качество данных определяют качество выходной модели. Для обучения текущих моделей искусственного интеллекта данные определяют языковые способности, понимание и даже ценности и гуманизированное поведение модели. На сегодняшний день дилемма в области потребности в данных для искусственного интеллекта в основном сосредоточена на следующих четырех аспектах:
- Голод данных: обучение модели искусственного интеллекта тесно связано с большим объемом входных данных. Из общедоступной информации следует, что количество параметров для обучения GPT-4 OpenAI достигло уровня в триллион.
- Качество данных: Совместно с использованием искусственного интеллекта и различных отраслей появились новые требования к своевременности, разнообразию, профессионализму отраслевых данных, а также к использованию новых источников данных, таких как настроения в социальных медиа.
- Проблемы конфиденциальности и соблюдения: В настоящее время различные страны и предприятия постепенно осознают важность высококачественных наборов данных и налагают ограничения на сбор данных.
- Высокие затраты на обработку данных: большие объемы данных, сложная обработка. Общедоступная информация показывает, что более 30% затрат ИИ-компаний на НИОКР используются на базовый сбор и обработку данных.
В настоящее время решение web3 отражается в следующих четырех аспектах:
1. Сбор данных: свободно доступные данные реального мира для парсинга быстро истощаются, и расходы компаний по искусственному интеллекту на данные увеличиваются из года в год. Однако в то же время эти расходы не передаются реальным поставщикам данных; платформы полностью наслаждаются созданием ценности, приносимой данными, например, Reddit заработал $203 миллиона за счет лицензионных соглашений на использование данных с компаниями по искусственному интеллекту.
Видение Web3 заключается в том, чтобы позволить пользователям, которые действительно вносят свой вклад, также участвовать в создании ценности, приносимой данными, и получать более личные и ценные данные пользователей в экономичной форме через распределенные сети и инцентивные механизмы.
- Поскольку Grass является децентрализованным уровнем данных и сетью, пользователи могут захватывать данные в реальном времени из всего Интернета, запуская узлы Grass, вкладывая неиспользуемую полосу пропускания и ретранслируя трафик, и получать токеновые вознаграждения;
- Vana представляет уникальную концепцию Пула Жидкости Данных (DLP), где пользователи могут загрузить свои личные данные (такие как данные о покупках, привычки в интернете, деятельность в социальных медиа и т. д.) на конкретный DLP и выбирать, разрешать ли использование этих данных для конкретных сторонних лиц;
- В PublicAI пользователи могут использовать #AI или #Web3 в качестве тегов классификации на Х@PublicAIСбор данных можно осуществить.
2. Предварительная обработка данных: При обработке данных в области искусственного интеллекта, поскольку собранные данные обычно содержат шум и ошибки, их необходимо очистить и преобразовать в удобный формат перед обучением модели, включая повторяющиеся задачи стандартизации, фильтрации и обработки отсутствующих значений. Этот этап является одним из немногих ручных процессов в индустрии искусственного интеллекта, который породил индустрию аннотаторов данных. Поскольку требования модели к качеству данных растут, порог для аннотаторов данных также повышается. Эта задача естественным образом подходит для децентрализованного стимулирующего механизма Web3.
- В настоящее время Grass и OpenLayer оба рассматривают возможность добавления аннотации данных в качестве ключевого шага.
- Synesis предложил концепцию 'Train2earn', акцентируя внимание на качестве данных, где пользователи могут быть вознаграждены за предоставление аннотированных данных, комментариев или других форм ввода.
- Проект маркировки данных Sapien игровым образом представляет задачи маркировки и позволяет пользователям ставить очки, чтобы заработать больше очков.
3. Конфиденциальность и безопасность данных: Необходимо уточнить, что конфиденциальность данных и безопасность данных - это два разных концепта. Конфиденциальность данных заключается в обработке чувствительных данных, в то время как безопасность данных защищает информацию от несанкционированного доступа, уничтожения и кражи. В результате преимущества и потенциальные сценарии применения технологий конфиденциальности Web3 отражаются в двух аспектах: (1) тренировка чувствительных данных; (2) сотрудничество по данным: несколько владельцев данных могут участвовать в обучении ИИ вместе, не раскрывая свои исходные данные.
Общие технологии конфиденциальности в Web3 в настоящее время включают:
- Доверенная среда выполнения (TEE), такая как Super Protocol;
- Полностью гомоморфное шифрование (FHE), такое как BasedAI, Fhenix.io или Inco Network;
- Технология нулевого знания (zk), такая как Протокол Восстановления, использующий технологию zkTLS, генерирует доказательства нулевого знания трафика HTTPS, позволяя пользователям безопасно импортировать данные об активности, репутации и идентичности с внешних веб-сайтов, не раскрывая чувствительную информацию.
Однако область все еще находится в начальной стадии, большинство проектов все еще находятся на стадии исследований. В настоящее время одной из дилемм является то, что затраты на вычисления слишком высоки, приводя к невозможности реализации некоторых примеров:
- Фреймворк zkML EZKL занимает около 80 минут для генерации доказательства модели 1M-nanoGPT.
- По данным Modulus Labs, накладные расходы zkML более чем в 1000 раз превышают чистые вычисления.
4. Хранение данных: Получив данные, необходимо иметь место для их хранения на цепочке и использовать LLM, сгенерированный данными. С доступностью данных (DA) в качестве ключевой проблемы, до обновления Ethereum Danksharding его пропускная способность была 0,08 МБ. В то же время для обучения и реального времени вывода моделей искусственного интеллекта обычно требуется пропускная способность данных от 50 до 100 ГБ в секунду. Это различие порядка делает существующие решения на цепочке недостаточными, когда речь идет о 'ресурсоемких приложениях искусственного интеллекта'.
- 0g.AI - представительный проект в этой категории. Это централизованное хранилище, разработанное для высокопроизводительных требований искусственного интеллекта, с ключевыми особенностями, включая высокую производительность и масштабируемость, поддерживающее быструю загрузку и скачивание крупномасштабных наборов данных с помощью передовых технологий шардинга и кодирования стирания, обеспечивающих скорость передачи данных до 5 ГБ в секунду.
Two, Middleware: Обучение и вывод модели
Децентрализованный рынок на основе модели с открытым исходным кодом
Дебаты о том, должны ли модели искусственного интеллекта быть открытыми или закрытыми, никогда не прекращались. Совокупная инновация, приносимая открытым исходным кодом, является преимуществом, которое закрытые модели не могут соперничать. Однако при отсутствии модели без прибыли, как открытые модели могут повысить мотивацию разработчика? Это направление стоит обдумать. Основатель Baidu, Робин Ли, заявил в апреле этого года: «Модели открытого исходного кода будут отстаивать все больше и больше».
В этом отношении Web3 предлагает возможность децентрализованного рынка моделей с открытым исходным кодом, то есть токенизации самой модели, резервирования определенной доли токенов для команды и направления части будущего дохода модели держателям токенов.
- Протокол Bittensor устанавливает модель открытого исходного кода P2P-рынка, состоящую из десятков «подсетей», где поставщики ресурсов (вычисления, сбор/хранение данных, таланты машинного обучения) конкурируют друг с другом, чтобы достичь целей конкретных владельцев подсетей. Подсети могут взаимодействовать и учиться друг у друга, тем самым достигая большей интеллектуальности. Награды распределяются путем голосования сообщества и дальнейшего распределения среди подсетей на основе конкурентоспособной производительности.
- ORA introduces the concept of Initial Model Offering (IMO), tokenizing AI models for purchase, sale, and development on decentralized networks.
- Sentient, платформа децентрализованного искусственного общего интеллекта, стимулирует людей к сотрудничеству, созданию, репликации и расширению моделей искусственного интеллекта, вознаграждая участников.
- Spectral Nova фокусируется на создании и применении моделей искусственного интеллекта и машинного обучения.
Проверяемое заключение
Для дилеммы 'черного ящика' в процессе рассуждения ИИ стандартным решением Web3 является наличие нескольких валидаторов, повторяющих одну и ту же операцию и сравнивающих результаты. Однако из-за текущего дефицита высокопроизводительных 'Nvidia чипов' очевидным вызовом, стоящим перед этим подходом, является высокая стоимость рассуждения ИИ.
Более многообещающим решением является выполнение ZK-доказательств вычислений вывода ИИ вне цепи, где один доказатель может доказать другому верификатору, что заданное утверждение верно, не раскрывая никакой дополнительной информации, кроме самого утверждения верности, обеспечивая безразрешение проверки вычислений модели ИИ в цепи. Для этого требуется доказать в зашифрованном виде в цепи, что внеключевые вычисления были правильно завершены (например, набор данных не был подвергнут вмешательству), обеспечивая при этом конфиденциальность всех данных.
Основные преимущества включают в себя:
- Масштабируемость: Доказательства нулевого знания могут быстро подтвердить большое количество внелановых вычислений. Даже при увеличении числа транзакций одно доказательство нулевого знания может проверить все транзакции.
- Защита конфиденциальности: Подробная информация о данных и моделях искусственного интеллекта хранится в тайне, в то время как все стороны могут проверить, что данные и модели не были изменены.
- Не нужно доверять: вы можете подтвердить вычисление, не полагаясь на централизованные стороны.
- Интеграция Web2: По определению, Web2 интегрирован вне цепи, что означает, что проверяемое рассуждение может помочь привести его наборы данных и вычисления ИИ на цепь. Это помогает улучшить принятие Web3.
В настоящее время технология проверки Web3 для верификации рассуждений следующая:
- ZKML: Сочетание нулевого доказательства с машинным обучением для обеспечения конфиденциальности данных и моделей, позволяя верифицируемые вычисления без раскрытия определенных внутренних свойств. Компания Modulus Labs выпустила доказательство ZK на основе ZKML для построения искусственного интеллекта, чтобы эффективно проверять, корректно ли выполнены алгоритмы манипулирования провайдеров искусственного интеллекта на цепочке, но в настоящее время клиенты в основном являются он-чейн DApps.
- opML: Используя принцип оптимистичной агрегации, проверяя время возникновения спора, улучшая масштабируемость и эффективность вычислений ML, в этой модели нужно проверить только небольшую часть результатов, сгенерированных 'валидатором', но снижение экономических затрат установлено достаточно высоко, чтобы увеличить стоимость мошенничества валидаторов и сохранить избыточные вычисления.
- TeeML: Используйте доверенную среду выполнения для безопасного выполнения вычислений ML, защищая данные и модели от вмешательства и несанкционированного доступа.
Три, Уровень приложения: Искусственный интеллект Агент
Текущее развитие искусственного интеллекта уже показало сдвиг в фокусе с модельных возможностей на ландшафт искусственного интеллекта. Технологические компании, такие как OpenAI, AI-единорог Anthropic, Microsoft и т. д., обращаются к развитию искусственного интеллекта, пытаясь преодолеть текущий технический плато LLM.
OpenAI определяет AI Agent как систему, управляемую LLM как своим мозгом, обладающую способностью автономно понимать восприятие, планировать, помнить и использовать инструменты, а также способную автоматически выполнять сложные задачи. Когда искусственный интеллект переходит от быть инструментом, используемым к субъекту, который может использовать инструменты, он становится AI Agent. Вот почему AI Agents могут стать наиболее идеальными интеллектуальными ассистентами для людей.
Что может принести Web3 Agent?
1. Децентрализация
Децентрализация Web3 может сделать систему Agent более децентрализованной и автономной. Системы стимулирования и штрафов для стейкеров и делегатов могут способствовать демократизации системы Agent, и GaiaNet, Theoriq и HajimeAI пытаются сделать это.
2, Cold Start
Разработка и итерация AI Agent часто требуют большого финансового поддержки, и Web3 может помочь многообещающим проектам AI Agent получить финансирование на ранних этапах и холодный старт.
- Virtual Protocol запускает платформу создания и выпуска токенов AI Agent fun.virtuals, где любой пользователь может развернуть AI Agent с одним щелчком и достичь 100% честного распределения токенов AI Agent.
- Spectral предложил концепцию продукта, поддерживающую выпуск активов AI Agent на цепочке: выпуск токенов через IAO (Initial Agent Offering), AI Agents могут напрямую получать средства от инвесторов, становясь при этом участником управления DAO, предоставляя инвесторам возможность участвовать в развитии проекта и делиться будущими прибылями.
Как искусственный интеллект усиливает Web3?
Влияние искусственного интеллекта на проекты Web3 очевидно, поскольку он приносит пользу технологии блокчейн путем оптимизации операций on-chain (таких как выполнение смарт-контрактов, оптимизация ликвидности и принятие решений на основе искусственного интеллекта). В то же время он также может обеспечивать лучшие данные для принятия решений, улучшать безопасность on-chain и заложить основу для новых приложений на основе Web3.
Один, искусственный интеллект и финансы на цепи
Искусственный интеллект и криптоэкономика
31 августа генеральный директор Coinbase Брайан Армстронг объявил о первой зашифрованной транзакции AI-to-AI в сети Base, отметив, что AI-агенты теперь могут проводить транзакции с людьми, продавцами или другими ИИ на Base, используя доллары США, сделки моментальные, глобальные и бесплатные.
Помимо платежей, Luna протокола Virtuals впервые продемонстрировала, как AI Agents автономно выполняют транзакции on-chain, привлекая внимание и позиционируя AI Agents как интеллектуальные сущности, способные воспринимать окружающую среду, принимать решения и действовать, таким образом, рассматриваясь как будущее on-chain финансов. В настоящее время потенциальные сценарии для AI Agents следующие:
1. Сбор информации и прогнозирование: Помощь инвесторам в сборе объявлений биржи, общественной информации о проекте, панических эмоций, рисков общественного мнения и т. д., анализ и оценка фундаментальных активов, рыночных условий в реальном времени, а также прогнозирование тенденций и рисков.
2. Управление активами: предоставление пользователям подходящих инвестиционных целей, оптимизация распределения активов и автоматическое исполнение сделок.
3. Финансовый опыт: Помогите инвесторам выбрать самый быстрый метод торговли on-chain, автоматизируйте ручные операции, такие как межцепочные транзакции и корректировка газовых сборов, снизьте порог и стоимость он-чейн финансовых действий.
Представьте себе такой сценарий: вы даете инструкции ИИ-агенту следующим образом: «У меня есть 1000USDT, помогите мне найти комбинацию с наибольшим доходом с периодом блокировки не более одной недели». ИИ-агент даст следующий совет: «Я предлагаю начальное распределение 50% в A, 20% в B, 20% в X и 10% в Y. Я буду отслеживать процентные ставки и наблюдать за изменениями их уровней риска, и перебалансирую при необходимости». Кроме того, поиск потенциальных проектов с аирдропом и популярные знаки сообщества проектов Memecoin - все это возможные действия для ИИ-агента в будущем.

Источник изображения: Biconomy
В настоящее время кошельки AI Agent Bitte и протокол взаимодействия с ИИ Wayfinder предпринимают такие попытки. Они все пытаются получить доступ к API модели OpenAI, что позволяет пользователям командовать агентами для выполнения различных операций на цепи в интерфейсе чата, аналогичном ChatGPT. Например, первый прототип, выпущенный WayFinder в апреле этого года, продемонстрировал четыре основные операции: обмен, отправка, мост и стейкинг на основных сетях Base, Polygon и Ethereum.
В настоящее время децентрализованная платформа Agent Morpheus также поддерживает разработку таких агентов, как показано Biconomy, демонстрируя процесс, при котором разрешения кошелька не требуются для авторизации AI Agent на обмен ETH на USDC.
Искусственный интеллект и безопасность транзакций на цепочке
В мире Web3 безопасность транзакций на цепи является ключевой. Технология искусственного интеллекта может быть использована для улучшения безопасности и защиты конфиденциальности транзакций на цепи, с потенциальными сценариями, включая:
Мониторинг торговли: Технология обработки данных в реальном времени отслеживает аномальную торговую деятельность, обеспечивая инфраструктуру реального времени предупреждения для пользователей и платформ.
Анализ рисков: Помогите платформе проанализировать данные о поведении клиентов при торговле и оценить их уровень риска.
Например, платформа безопасности Web3 SeQure использует искусственный интеллект для обнаружения и предотвращения вредоносных атак, мошеннического поведения и утечек данных, а также обеспечивает механизмы мониторинга в реальном времени и оповещения для обеспечения безопасности и стабильности транзакций в сети. К таким же инструментам безопасности относятся работающие на искусственном интеллекте Sentinel.
Во-вторых, искусственный интеллект и инфраструктура on-chain
Искусственный интеллект и он-чейн данные
Технология AI играет важную роль в сборе и анализе данных on-chain, таких как:
- Web3 Аналитика: платформа аналитики на основе искусственного интеллекта, использующая алгоритмы машинного обучения и добычи данных для сбора, обработки и анализа данных on-chain.
- MinMax AI: Он предоставляет инструменты анализа данных на основе искусственного интеллекта on-chain для помощи пользователям в обнаружении потенциальных рыночных возможностей и тенденций.
- Kaito: веб-платформа поиска Web3 на основе поискового движка LLM.
- Следующее: интегрировано с ChatGPT, собирает и интегрирует соответствующую информацию, разбросанную по различным веб-сайтам и сообщественным платформам для представления.
- Другой сценарий применения - это оракул, искусственный интеллект может получать цены из нескольких источников для предоставления точных данных о ценообразовании. Например, Upshot использует искусственный интеллект для оценки волатильных цен на NFT, предоставляя процентную ошибку от 3 до 10% благодаря более чем ста миллионам оценок в час.
Искусственный интеллект и разработка&Audit
Недавно в сообществе разработчиков много внимания привлек веб-редактор искусственного интеллекта Web2 под названием Cursor. На его платформе пользователям достаточно описать естественным языком, и Cursor автоматически сгенерирует соответствующий HTML, CSS и JavaScript код, что значительно упрощает процесс разработки программного обеспечения. Эта логика также применима к повышению эффективности разработки Web3.
В настоящее время развертывание смарт-контрактов и DApps на публичных цепочках обычно требует использования эксклюзивных языков разработки, таких как Solidity, Rust, Move и т. д. Видение новых языков разработки заключается в расширении пространства проектирования децентрализованных блокчейнов, делая его более подходящим для разработки DApp. Однако, учитывая значительный дефицит разработчиков Web3, образование разработчиков всегда было более сложной проблемой.
В настоящее время искусственный интеллект в помощи развитию Web3 можно представить в сценариях, включая: автоматическое создание кода, проверку и тестирование смарт-контрактов, развертывание и обслуживание DApps, интеллектуальное завершение кода, ответы на сложные вопросы разработки в диалогах AI и т. д. При поддержке искусственного интеллекта это не только помогает повысить эффективность и точность разработки, но также снижает порог программирования, позволяя непрограммистам превратить свои идеи в практические приложения, принося новую жизненность в развитие децентрализованной технологии.
В настоящее время наиболее привлекательной является платформа запуска токенов одним щелчком, такая как Clanker, разработанный на основе ИИ «Токен-бот», предназначенный для быстрого развертывания токенов DIY. Вам просто нужно пометить Clanker на клиентах протокола SocialFi Farcaster, таких как Warpcast или Supercast, рассказать ему свою идею токена, и он запустит токен для вас на общедоступной цепи Base.
Также существуют платформы разработки контрактов, такие как Spectral, которые предоставляют функции генерации и развертывания смарт-контрактов одним нажатием кнопки, чтобы снизить порог разработки Web3, позволяя даже начинающим пользователям компилировать и разворачивать смарт-контракты.
В аудите веб-платформы Web3 проверочная платформа Fuzzland использует искусственный интеллект для помощи аудиторам в проверке уязвимостей кода, предоставляя естественноязыковые объяснения для помощи аудиторам-профессионалам. Fuzzland также использует искусственный интеллект для предоставления естественноязыковых объяснений формальных спецификаций и кода контракта, а также некоторого образца кода для помощи разработчикам в понимании потенциальных проблем в коде.
Три, искусственный интеллект и новая история Web3
Развитие генеративного искусственного интеллекта открывает новые возможности для новой нравственной истории Web3.
NFT: AI внедряет творчество в генеративные NFT. С помощью технологии искусственного интеллекта можно создавать разнообразные уникальные произведения и персонажи. Эти генеративные NFT могут стать персонажами, реквизитом или элементами сцены в играх, виртуальных мирах или метавселенных, например, в Bicasso под управлением Binance, где пользователи могут создавать NFT, загружая изображения и вводя ключевые слова для вычислений с помощью искусственного интеллекта. Аналогичные проекты включают Solvo, Nicho, IgmnAI и CharacterGPT.
GameFi: С естественным генерированием языка, созданием изображений и возможностями интеллектуальных NPC вокруг искусственного интеллекта ожидается, что GameFi улучшит эффективность и инновации в производстве игрового контента. Например, первая цепная игра Binaryx AI Hero позволяет игрокам исследовать различные варианты сюжета через случайность ИИ; аналогично, существует игра виртуального компаньона Sleepless AI, где игроки могут разблокировать персонализированный геймплей через различные взаимодействия на основе AIGC и LLM.
DAO: В настоящее время также предполагается, что искусственный интеллект будет применяться в DAO для отслеживания взаимодействия сообщества, записи взносов, награждения наиболее активных участников, доверительного голосования и т. д. Например, ai16z использует искусственного интеллекта для сбора информации о рынке on-chain и off-chain, анализа консенсуса сообщества и принятия инвестиционных решений в сочетании с предложениями членов DAO.
Значимость интеграции AI+Web3: Tower and Square
В самом сердце Флоренции, Италия, находится центральная площадь, самое важное политическое собрание для местных жителей и туристов. Здесь стоит 95-метровая муниципальная ратуша, создающая драматический эстетический эффект с площадью, вдохновляющая профессора истории Гарвардского университета Нила Фергюсона исследовать мировую историю сетей и иерархий в его книге «Площадь и башня», показывая пульсацию этих двух явлений со временем.
Этот прекрасный метафора не является неуместным, когда применяется к отношениям между искусственным интеллектом и Web3 сегодня. Глядя на долгосрочные, нелинейные исторические отношения между этими двумя сферами, можно увидеть, что квадраты более вероятно порождают новые и творческие вещи, чем башни, но башни по-прежнему имеют свою законность и сильную жизнеспособность.
С возможностью кластеризации энергии вычислительной мощности данных в технологических компаниях, искусственный интеллект разблокировал беспрецедентное воображение, заставляя крупных технологических гигантов делать крупные ставки, представляя различные итерации от различных чат-ботов до 'базовых больших моделей' типа GPT-4, GP4-4o. Автоматический программировочный робот (Devin) и Sora, с предварительными способностями имитировать реальный физический мир, появились один за другим, бесконечно усиливая воображение искусственного интеллекта.
В то же время ИИ в основном является отраслью крупного масштаба и централизованной, и эта технологическая революция вытолкнет технологические компании, которые постепенно приобрели структурное доминирование в 'интернет-эпоху', на более узкую высокую точку. Огромная мощь, монопольный денежный поток и огромные наборы данных, необходимые для доминирования в эпоху искусственного интеллекта, формируют более высокие барьеры для этого.
По мере роста башни и уменьшения решающих лиц за кулисами централизация искусственного интеллекта приносит много скрытых опасностей. Как толпы, собравшиеся на площади, могут избежать теней под башней? Это проблема, которую надеется решить Web3.
По сути, встроенные свойства блокчейна улучшают системы искусственного интеллекта и открывают новые возможности, в основном:
- В эпоху искусственного интеллекта 'код есть закон' - достижение прозрачных правил автоматического выполнения системы через смарт-контракты и шифрование верификации, предоставление вознаграждения аудитории ближе к цели.
- Экономика токенов - создание и координация поведения участников через токен-механизм, стейкинг, снижение, токен-награды и штрафы.
- Децентрализованное управление - побуждает нас задавать вопросы источникам информации и поощряет более критический и проницательный подход к технологиям искусственного интеллекта, предотвращая предвзятость, дезинформацию и манипуляцию и, в конечном итоге, способствуя появлению информированного и усиленного общества.
Развитие искусственного интеллекта также придало новый импульс Web3, возможно, влияние Web3 на искусственный интеллект требует времени для доказательства, но влияние искусственного интеллекта на Web3 немедленно: будь то безумие Meme или помощь ИИ агента в снижении порога входа для онлайн-приложений, это все очевидно.
Когда Web3 определяется как самоуспокоение небольшой группы людей, а также как запутанность в сомнениях о воспроизведении традиционных отраслей, добавление искусственного интеллекта приносит предсказуемое будущее: более стабильная и масштабируемая пользовательская база Web2, более инновационные бизнес-модели и услуги.
Мы живем в мире, где «башни и квадраты» сосуществуют, хотя ИИ и Web3 имеют разные временные шкалы и отправные точки, их конечная цель — как сделать так, чтобы машины лучше служили человечеству, и никто не может дать определение стремительной реке. Мы с нетерпением ждем будущего AI+Web3.
Утверждение:
- Эта статья воспроизведена с [GateTechFlow], авторское право принадлежит автору оригинала [Coinspire],пожалуйста, свяжитесь с нами, если у вас есть возражения к перепечатке Команда Gate Learn, команда обработает это как можно скорее в соответствии с соответствующими процедурами.
- Отказ от ответственности: Взгляды и мнения, высказанные в этой статье, являются исключительно мнением автора и не являются инвестиционными советами.
- Статья переведена на другие языки командой Gate Learn, если не указаноGate.ioПод никаким обстоятельством переведенные статьи не могут быть скопированы, распространены или использованы без разрешения.
Похожие статьи

Что такое Tronscan и как вы можете использовать его в 2025 году?

Что такое OpenLayer? Все, что вам нужно знать о OpenLayer

Что такое индикатор кумулятивного объема дельты (CVD)? (2025)

Что такое Нейро? Все, что вам нужно знать о NEIROETH в 2025 году

Что такое Solscan и как его использовать? (Обновление 2025 года)
