- Topic1/3
15k Popularity
34k Popularity
18k Popularity
6k Popularity
172k Popularity
- Pin
- Hey fam—did you join yesterday’s [Show Your Alpha Points] event? Still not sure how to post your screenshot? No worries, here’s a super easy guide to help you win your share of the $200 mystery box prize!
📸 posting guide:
1️⃣ Open app and tap your [Avatar] on the homepage
2️⃣ Go to [Alpha Points] in the sidebar
3️⃣ You’ll see your latest points and airdrop status on this page!
👇 Step-by-step images attached—save it for later so you can post anytime!
🎁 Post your screenshot now with #ShowMyAlphaPoints# for a chance to win a share of $200 in prizes!
⚡ Airdrop reminder: Gate Alpha ES airdrop is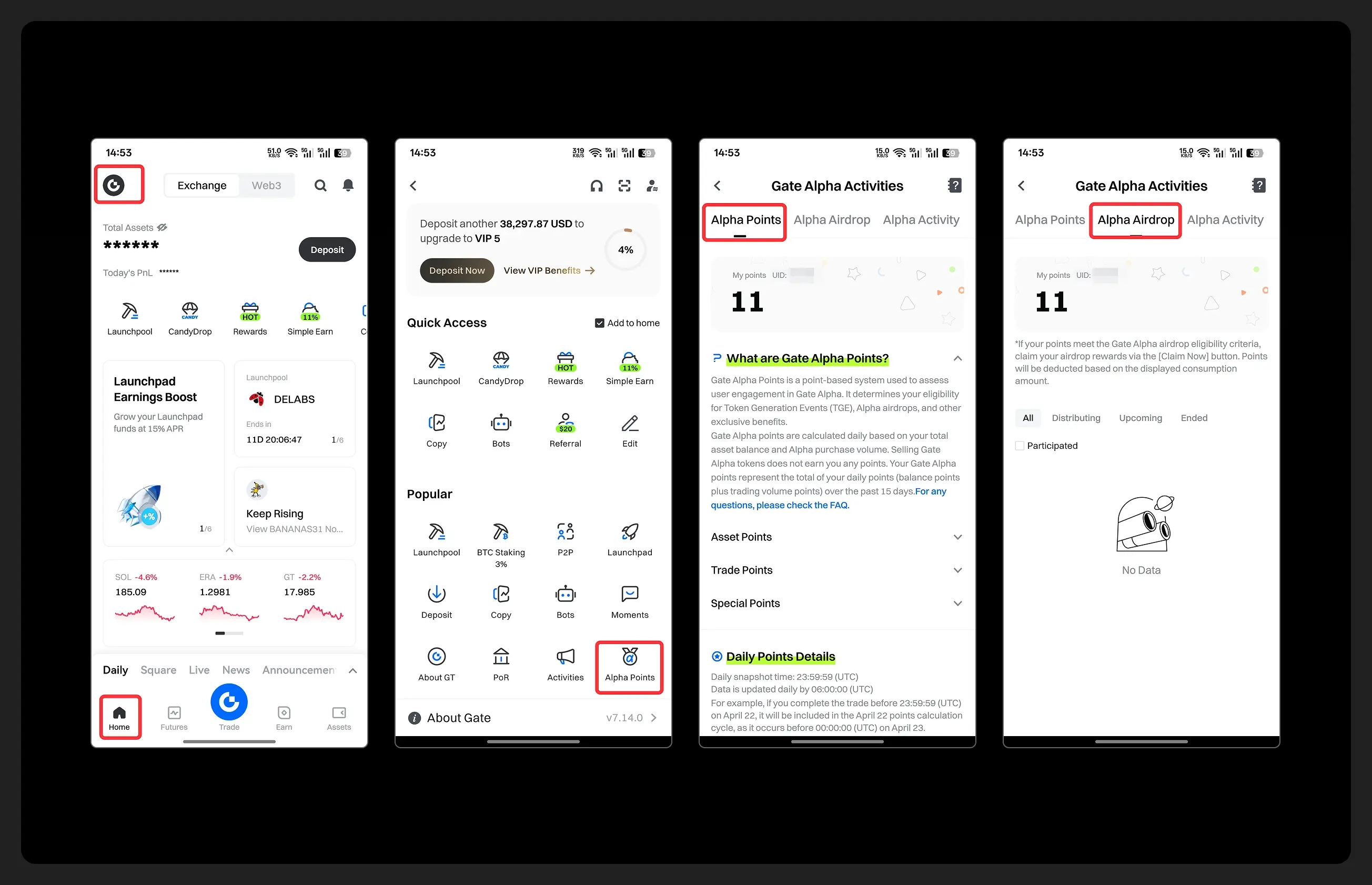
- Gate Futures Trading Incentive Program is Live! Zero Barries to Share 50,000 ERA
Start trading and earn rewards — the more you trade, the more you earn!
New users enjoy a 20% bonus!
Join now:https://www.gate.com/campaigns/1692?pid=X&ch=NGhnNGTf
Event details: https://www.gate.com/announcements/article/46429
- Hey Square fam! How many Alpha points have you racked up lately?
Did you get your airdrop? We’ve also got extra perks for you on Gate Square!
🎁 Show off your Alpha points gains, and you’ll get a shot at a $200U Mystery Box reward!
🥇 1 user with the highest points screenshot → $100U Mystery Box
✨ Top 5 sharers with quality posts → $20U Mystery Box each
📍【How to Join】
1️⃣ Make a post with the hashtag #ShowMyAlphaPoints#
2️⃣ Share a screenshot of your Alpha points, plus a one-liner: “I earned ____ with Gate Alpha. So worth it!”
👉 Bonus: Share your tips for earning points, redemption experienc
- 🎉 The #CandyDrop Futures Challenge is live — join now to share a 6 BTC prize pool!
📢 Post your futures trading experience on Gate Square with the event hashtag — $25 × 20 rewards are waiting!
🎁 $500 in futures trial vouchers up for grabs — 20 standout posts will win!
📅 Event Period: August 1, 2025, 15:00 – August 15, 2025, 19:00 (UTC+8)
👉 Event Link: https://www.gate.com/candy-drop/detail/BTC-98
Dare to trade. Dare to win.
The new bottleneck in the AI industry: on-chain data becomes the key resource to change the game.
New Challenges in the AI Era: Data Becomes the Core Bottleneck
With the rapid growth of artificial intelligence model scale and computing power, a long-ignored issue is gradually surfacing - data supply. The structural contradiction currently faced by the AI industry is no longer about model architecture or chip computing power, but how to transform fragmented human behavioral data into verifiable, structured, AI-friendly resources. This insight not only reveals the current predicament of AI development but also outlines a brand new "Data Finance ( DataFi ) era" - in this era, data will become a core production factor that is measurable, tradable, and value-added, just like electricity and computing power.
From Computing Power Competition to Data Shortage
The development of AI has long been driven by the "model-computing power" dual mechanism. Since the deep learning revolution, model parameters have jumped from millions to trillions, and the demand for computing power has grown exponentially. The cost of training an advanced large language model has exceeded 100 million dollars, with 90% of that going towards GPU cluster rentals. However, as the industry focuses on "larger models" and "faster chips," a crisis on the data supply side is quietly approaching.
The "organic data" generated by humans has reached a growth ceiling. Taking text data as an example, the total amount of high-quality text available publicly on the internet is approximately 10^12 words, while training a model with 100 billion parameters requires about 10^13 words of data. This means that the existing data pool can only support the training of 10 models of the same scale. Even more severely, the proportion of duplicate data and low-quality content exceeds 60%, further compressing the supply of effective data. When models begin to "devour" the data they generate themselves, the performance degradation of the model caused by "data pollution" has become a concern in the industry.
The root of this contradiction lies in the fact that the AI industry has long viewed data as "free resources" rather than "strategic assets" that require careful nurturing. While models and computing power have formed a mature market system, the production, cleaning, verification, and trading of data are still in the "primitive era". Industry experts emphasize that the next decade for AI will be the decade of "data infrastructure", and the on-chain data from encrypted networks is the key to unlocking this dilemma.
On-chain Data: The "Human Behavior Database" Most Needed by AI
Against the backdrop of data scarcity, on-chain data from crypto networks is showcasing unique value. Compared to traditional internet data, on-chain data inherently possesses the authenticity of "incentive alignment" - every transaction, every contract interaction, and every wallet address's behavior is directly linked to real capital and is immutable. This data is defined as "the most concentrated data of human incentive-aligned behavior on the internet," reflected in three dimensions:
Real-world "intent signals": On-chain data records decision-making behavior backed by real monetary votes, rather than emotional comments or random clicks. This type of data, "endorsed by capital", is highly valuable for training AI's decision-making capabilities.
Traceable "Behavior Chain": The transparency of blockchain allows for the complete tracing of user actions. The historical transactions, interaction protocols, and asset changes of a wallet address constitute a coherent "behavior chain". This structured behavioral data is precisely the "human reasoning samples" that current AI models lack the most.
Open ecosystem "permissionless access": On-chain data is open and permissionless, providing a "barrier-free" data source for AI model training. However, this openness also presents challenges: on-chain data exists in the form of "event logs" and needs to be cleaned, standardized, and correlated before it can be used by AI models. Currently, the "structural conversion rate" of on-chain data is less than 5%, with a large number of high-value signals buried among billions of fragmented events.
Super Data Network: The "Operating System" for On-Chain Data
To solve the problem of fragmented on-chain data, the industry has proposed the concept of a super data network - a "smart on-chain operating system" designed specifically for AI. Its core goal is to convert scattered on-chain signals into structured, verifiable, and real-time combinable AI-friendly data. It mainly includes the following components:
Open Data Standards: Standardize the definition and description of on-chain data to ensure that AI models can directly "understand" the business logic behind the data without needing to adapt to different chains or protocol data formats.
Data validation mechanism: Ensures the authenticity of data through Ethereum's AVS( Active Validator Set) mechanism. The validator nodes verify the integrity and accuracy of on-chain data, solving the trust issues of traditional centralized data validation.
High throughput data availability layer: By optimizing data compression algorithms and transmission protocols, real-time processing of hundreds of thousands of on-chain events per second is achieved, meeting the low latency and high throughput data requirements of AI applications.
DataFi Era: Data Becomes a Tradable "Capital"
The ultimate goal of the Super Data Network is to drive the AI industry into the DataFi era - data is no longer a passive "training material", but an active "capital" that can be priced, traded, and appreciated. The realization of this vision relies on transforming data into four core attributes:
Structured: Transforming raw on-chain data into structured data that can be directly utilized by AI models.
Composable: Structured data can be freely combined like LEGO bricks, expanding the application boundaries of data.
Verifiable: Ensure the authenticity and traceability of data through hash records on the blockchain.
Monetization: Data providers can directly monetize structured data, forming a value assessment system for the data.
In this DataFi era, data will become the bridge connecting AI with the real world. Trading agents perceive market sentiment through on-chain data, autonomous applications optimize services through user behavior data, and ordinary users gain continuous benefits by sharing data. Just as the power grid spurred the industrial revolution, the computing power network spurred the internet revolution, the super data network is giving rise to the "data revolution" of AI.
When we talk about the future of AI, we often focus on the "intelligence level" of the models while neglecting the "data soil" that supports this intelligence. The super data network reveals a core truth: the evolution of AI is essentially the evolution of data infrastructure. From the "limitations" of human-generated data to the "value discovery" of on-chain data, from the "disorder" of fragmented signals to the "order" of structured data, and from data as a "free resource" to DataFi as a "capital asset", this concept is reshaping the underlying logic of the AI industry.
Next-generation AI-native applications not only require models or wallets, but also need trustless, programmable, high-signal data. When data is finally given its due value, AI can truly unleash the power to change the world.